训练机器人操纵柔软和可变形的物体
嵌入了物理世界知识的虚拟环境可以加快解决问题的速度。机器人可以解出魔方并在火星崎岖的地形中航行,但它们很难完成一些简单的任务,比如擀出一块面团或处理一双筷子。即使有大量的数据、清晰的说明和广泛的培训,他们也很难处理孩子容易掌握的任务。
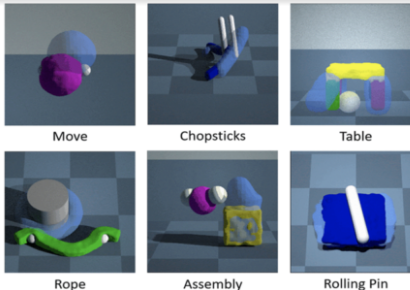
新的模拟环境 PlasticineLab旨在让机器人学习更加直观。通过将物理世界的知识构建到模拟器中,研究人员希望能够更轻松地训练机器人操纵现实世界的物体和材料,这些物体和材料经常弯曲和变形而不会恢复到原来的形状。该模拟器由麻省理工学院、麻省理工学院-IBM 沃森人工智能实验室和加州大学圣地亚哥分校的研究人员开发,在国际学习代表会议上推出。
新的模拟环境 PlasticineLab 旨在让机器人学习更加直观。像图中这样的任务旨在训练智能体操纵与现实世界中发现的物体相似的柔软且可变形的物体。图片来源:MIT-IBM Watson AI 实验室。
在 PlasticineLab 中,机器人代理通过在模拟中操纵各种软物体来学习如何完成一系列给定的任务。在 RollingPin 中,目标是通过压在一块面团上或用大头针在上面滚动来压扁它;在绳索中,将绳子缠绕在柱子上;在筷子中,拿起一根绳子并将其移动到目标位置。
他们说,研究人员通过将世界的物理知识嵌入模拟器来训练他们的代理以比在强化学习算法下训练的代理更快地完成这些和其他任务,这使他们能够利用基于梯度下降的优化技术来找到最佳的解决方案。
该研究的主要作者、前麻省理工学院-IBM 沃森人工智能实验室实习生、现为加州大学圣地亚哥分校博士生的黄志奥说:“将物理的基本知识编程到模拟器中可以提高学习过程的效率。” . “这让机器人对现实世界有更直观的感觉,那里充满了生物和可变形的物体。”
“机器人可能需要经过数千次迭代才能通过强化学习的试错技术来掌握一项任务,强化学习通常用于在模拟中训练机器人,”该工作的资深作者、 IBM 研究员Chuang Gan 说。 . “我们展示了通过烘焙一些物理知识可以更快地完成它,这允许机器人使用基于梯度的规划算法来学习。”
通过称为Taichi的图形编程语言,将基本物理方程烘焙到 PlasticineLab 中。太极和PlasticineLab 所基于的早期模拟器 ChainQueen都是由研究合著者Yuanming Hu SM '19, PhD '21 开发的。通过使用基于梯度的规划算法,PlasticineLab 中的智能体能够不断地将其目标与其在该点上所做的运动进行比较,从而更快地修正路线。
“我们可以通过反向传播找到最佳解决方案,与用于训练神经网络的技术相同,”该研究的合著者、麻省理工学院博士生陶杜说。“反向传播为代理提供了更新其动作以更快达到目标所需的反馈。”
这项工作是一项持续努力的一部分,旨在赋予机器人更多的常识,以便他们有一天能够在现实世界中做饭、打扫、叠衣服和执行其他平凡的任务。
标签: