用于符号回归的新型深度学习框架
劳伦斯利弗莫尔国家实验室 (LLNL) 计算机科学家开发了一个新框架和随附的可视化工具,该工具利用深度强化学习解决符号回归问题,在基准问题上优于基线方法。
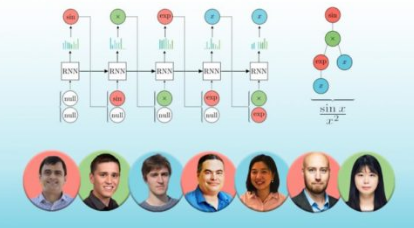
劳伦斯利弗莫尔国家实验室团队开发了一种新的深度强化学习框架,用于称为符号回归的离散优化类型,表明它可以在基准问题上胜过包括商业软件黄金标准在内的几种常用方法。这项工作正在即将举行的国际学习代表会议上展出。左起:LLNL 团队成员 Claudio Santiago、Brenden Petersen、Mikel Landajuela、Nathan Mudhenk、Soo Kim、Ruben Glatt 和 Joanne Kim。
该 论文 最近在国际学习表示会议(ICLR 2021)上作为口头报告被接受,该会议是世界顶级机器学习会议之一。该会议实际上于 5 月 3 日至 7 日举行。
在论文中,LLNL 团队描述了将深度强化学习应用于离散优化——处理离散“构建块”的问题,这些“构建块”必须以特定的顺序或配置组合以优化所需的属性。该团队专注于一种称为符号回归的离散优化——寻找适合从实验中收集的数据的简短数学表达式。符号回归旨在揭示物理过程的潜在方程或动力学。
“离散优化真的很有挑战性,因为你没有梯度。想象一个孩子在玩乐高积木,为一项特定任务组装一个装置——你可以更换一块乐高积木,突然之间,它们的特性就完全不同了,”主要作者布伦登·彼得森解释说。“但我们所展示的是,深度强化学习是有效搜索离散对象空间的一种非常强大的方法。”
彼得森继续说,虽然深度学习在解决许多复杂的任务方面取得了成功,但其结果在很大程度上对人类来说是无法解释的。“在这里,我们使用大型模型(即神经网络)来搜索小型模型(即简短的数学表达式)的空间,因此您可以两全其美。你在利用深度学习的力量,但得到你真正想要的,这是一个非常简洁的物理方程。”
Petersen 说,符号回归通常在机器学习和人工智能中使用进化算法进行处理。他解释说,进化方法的问题在于算法没有原则性,也不能很好地扩展。共同作者说,LLNL 的深度学习方法是不同的,因为它有理论支持并基于梯度信息,使其对科学家更容易理解和有用。
LLNL 的合著者 Mikel Landajuela 说:“这些进化方法基于随机突变,所以基本上在一天结束时,随机性在寻找正确答案方面起着重要作用。” “我们方法的核心是一个学习离散对象景观的神经网络;它保存了过程的记忆,并了解这些物体如何分布在这个巨大的空间中,以确定一个好的方向。这就是让我们的算法更好地工作的原因——传统方法缺少记忆和方向的结合。”
景观中可能的表达数量非常多,因此合著者克劳迪奥·圣地亚哥帮助为算法创建了不同类型的用户指定约束,以排除已知不是解决方案的表达,从而实现更快、更有效的搜索。
“DSR 框架允许考虑范围广泛的约束,从而大大减少搜索空间的大小,”圣地亚哥说。“这与进化方法不同,进化方法不能轻易有效地考虑约束。一般来说,不能保证在应用进化算子后约束会得到满足,这阻碍了它们对大型域的显着低效。”
对于这篇论文,该团队在一组符号回归问题上测试了该算法,表明它的表现优于几个常见的基准,包括商业软件黄金标准。
该团队一直在对薄膜压缩等现实世界的物理问题进行测试,并显示出有希望的结果。作者表示,该算法具有广泛的适用性,不仅适用于符号回归,还适用于任何类型的离散优化问题。他们最近开始将其应用于创建独特的氨基酸序列,以改善疫苗设计中与病原体的结合。
彼得森说,这项工作最令人兴奋的方面是它的潜力不是取代物理学家,而是与他们互动。为此,该团队 为该算法创建了一个 交互式可视化应用程序,物理学家可以使用它来帮助他们解决现实世界中的问题。
“这非常令人兴奋,因为我们真的刚刚打开了这个新框架,”彼得森说。“它与其他方法的真正区别在于,它能够以非常有原则的方式直接结合领域知识或先验信念。几年后,我们想象一个物理研究生使用它作为工具。随着他们获得更多信息或实验结果,他们可以与算法进行交互,为其提供新知识以帮助其磨练正确答案。”
这项工作源于实验室指导的研究和开发计划资助的颠覆性研究计划,该计划由被认为是高风险和高回报的项目组成。
标签: