研究人员训练神经网络识别研究论文中的化学式
来自Skoltech的初创公司Syntelly、莫斯科国立大学和Sirius大学的研究人员开发了一种基于神经网络的解决方案,用于自动识别研究论文扫描中的化学式。该研究发表在欧洲化学学会的科学期刊《化学方法》上。
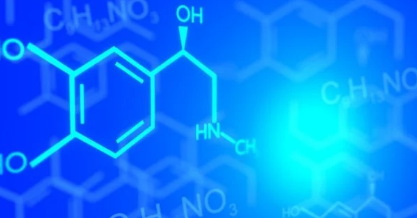
人类正在进入人工智能时代。现代深度学习方法也将改变化学,这总是需要大量定性数据来进行神经网络训练。
好消息是化学数据“老化得很好”。即使某种化合物最初是在100年前合成的,关于其结构、性质和合成方式的信息仍然与今天相关。即使在我们这个普遍数字化的时代,有机化学家也很可能会转向图书馆收藏的原始期刊论文或论文——例如早在20世纪初以德语出版——以获取有关研究不足的分子的信息.
坏消息是没有公认的标准方法来呈现化学公式。化学家通常使用许多技巧以简写符号的方式来表示熟悉的化学基团。例如,叔丁基的可能替代物包括“tBu”、“t-Bu”和“tert-Bu”。更糟糕的是,化学家经常使用一个带有不同“占位符”(R1、R2等)的模板来指代许多相似的化合物,但这些占位符符号可能在任何地方定义:在图形本身中,在运行文本中文章或补充。更不用说不同期刊的绘画风格会随着时间的推移而变化,化学家的个人习惯不同,惯例也会改变。结果,即使是专业的化学家有时也会发现自己在试图弄清他们在某些文章中发现的“谜题”时不知所措。对于计算机算法,
然而,当他们接近它时,研究人员已经有了使用Transformer解决类似问题的经验——Transformer是谷歌最初提出的用于机器翻译的神经网络。该团队没有在语言之间翻译文本,而是使用这个强大的工具将分子或分子模板的图像转换为其文本表示。这种表示称为功能组-SMILES。
令研究人员真正感到惊讶的是,只要相关的描绘风格在训练数据中得到体现,神经网络几乎可以学习任何东西。也就是说,Transformer需要数以千万计的示例进行训练,而手动从研究论文中收集这么多化学公式是不可能的。因此,该团队采用了另一种方法并创建了一个数据生成器,该数据生成器通过组合随机选择的分子片段和描述样式来生成分子模板的示例。
“我们的研究很好地证明了化学结构光学识别正在进行的范式转变。虽然先前的研究主要集中在分子结构识别本身,但现在我们拥有Transformer和类似网络的独特能力,我们可以转而致力于创建人工样本生成器,以模仿大多数现有的分子模板描述风格。我们的算法结合了分子、官能团、字体、样式,甚至印刷缺陷,它引入了一些额外的分子、抽象片段等。即使是化学家也很难判断分子是直接来自真实的纸还是来自发生器,”该研究的首席研究员谢尔盖·索斯宁(SergeySosnin)说,他是在Skoltech成立的初创公司Syntelly的首席执行官。
标签: